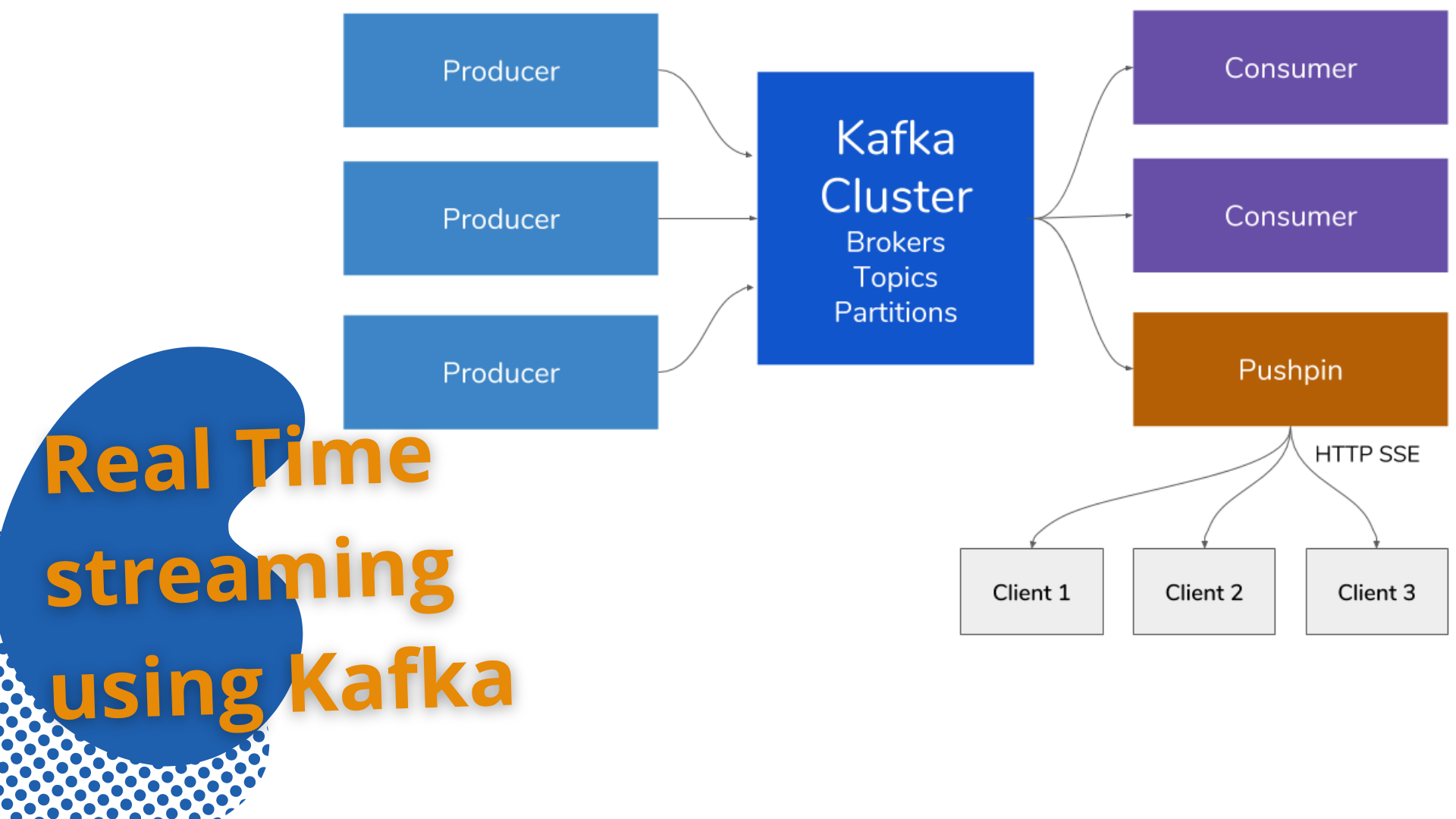
Team RV Global Solutions Inc. used Apache Kafka as our distributed streaming platform. At its core, it allowed systems that generated data (called Producers) to persist their data in real-time in an Apache Kafka Topic. Any topic could then be read by any number of systems who needed that data in real-time. Therefore, at its core, Kafka was a Pub/Sub system. Behind the scenes, Kafka was distributed, scaled well, replicated data across brokers (servers), had ability to survive broker downtime, and much more.
The target architecture
When building a real-time pipeline,our team considered the microservices. Microservices were small components designed to do one task very well. They interacted with one another, but not directly. Instead, they interacted indirectly by using an intermediary, in our case a Kafka topic. Therefore, the contract between two microservices was the data itself. That contract was enforced by leveraging schemas (more on that later). To summarise, our only job was to model the data.
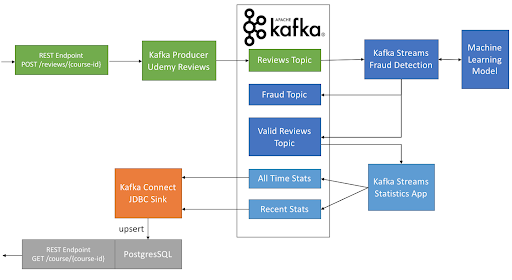
Here are the micro-services we are going to need:
- Review Kafka Producer: when a user posted a review to a REST Endpoint, it ended up in Kafka right away.
- Fraud Detector Kafka Streams: we got a stream of reviews. We were able to score these reviews for fraud using some real-time machine learning, and either validated them or flagged them as a fraud.
- Reviews Aggregator Kafka Streams: now that we had a stream of valid reviews, we aggregated them either since a course launch, or by only taking into account the last 90 days of reviews.
- Review Kafka Connect Sink: We now had a stream of updates for our course statistics. We needed to sink them in a PostgreSQL database so that other web services could pick them up and show them to the users and instructors.
Apache Kafka
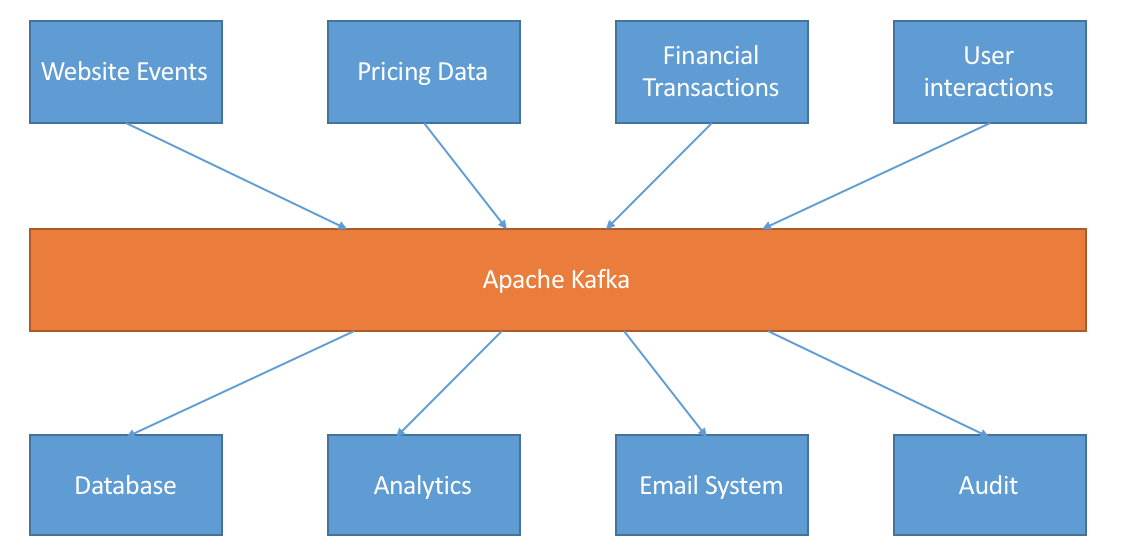
For Team RV Global Solutions Inc., Apache Kafka was our choice for an open-source distributed stream processing platform.
Our team describes Kafka as a collection of files, filled with messages that were distributed across multiple machines. Most of Kafka analogies revolved around tying these various individual logs together, routing messages from producers to consumers reliably, replicating for fault tolerance, and handling failure gracefully. The underlying abstraction was a partitioned log, essentially a set of append-only files spread over several machines. This encouraged sequential access patterns. A Kafka cluster was a distributed system that spread data over many machines both for fault tolerance and for linear scale-out.
Our team considered Kafka, a fully-fledged streaming platform for the following attributes:
- Scalable.
- Fault-tolerant.
- Publish-subscribe messaging system.
- Higher throughput compared with most messaging systems.
Kafka's Capabilities as a Streaming Platform
- Published and Subscribed to Streams of Records:At the heart of Kafka lies the humble, immutable commit log, and from there our team could subscribe to it, and publish data to any number of systems or real-time applications. Unlike messaging queues, Kafka was a highly scalable, fault-tolerant distributed system. Kafka had stronger ordering guarantees than a traditional messaging system. A traditional queue retained records in order on the server, and if multiple consumers consumed from the queue, the server handed out records in the order they were stored. However, although the server handed out records in order, the records were delivered asynchronously to consumers, so they arrived out of order to different consumers. Kafka did this more efficiently. Kafka provided both ordering guarantees and load balancing over a pool of consumer processes
- Stored Streams of Records in a Fault-Tolerant Durable Way:In Kafka, data was written to disk in a fault-tolerant way using replication of data. Kafka allowed our team to wait for acknowledgement for completion, and a write was not considered complete until it was fully replicated and guaranteed to persist even if the server failed. Kafka performed the same whether we had 50 KB or 50 TB of persistent data on the server. As a result, our team considers Kafka as a kind of special purpose distributed file system dedicated to high-performance, low-latency commit log storage, replication, and propagation.
- Processed Streams of Records as They Occur:A streaming platform would not be complete without the ability to manipulate data as it arrives. The Streams API within Apache Kafka was a powerful, lightweight library that allowed for on the fly processing.
In Kafka, a stream processor was anything that took continuous streams of data from input topics, performed some processing on this input, and produced continual streams of data to output topics.
Simple processing could be done directly using the producer and consumer APIs. For more complex transformations, Kafka provided a fully integrated Streams API.
Concepts in Apache Kafka
- Kafka was run as a cluster on one or more servers that could span multiple data centers.
- The Kafka cluster stored streams of records in categories called topics.
- Each record consisted of a key, a value, and a timestamp.
Kafka Use Cases
Kafka was used in two broad classes of applications. It could build real-time streaming data pipelines that reliably moved data between systems and applications. It could also be used to build real-time streaming applications that transformed or reacted to streams of data.
Some use cases for these include:
Messaging.
Real-time website activity tracking.
Metrics.
Log aggregation.
Stream processing.
Event sourcing.
Commit Log.