RVGS’s Seven key steps to implementing AI:
Step 1: Understand the difference between AI and ML
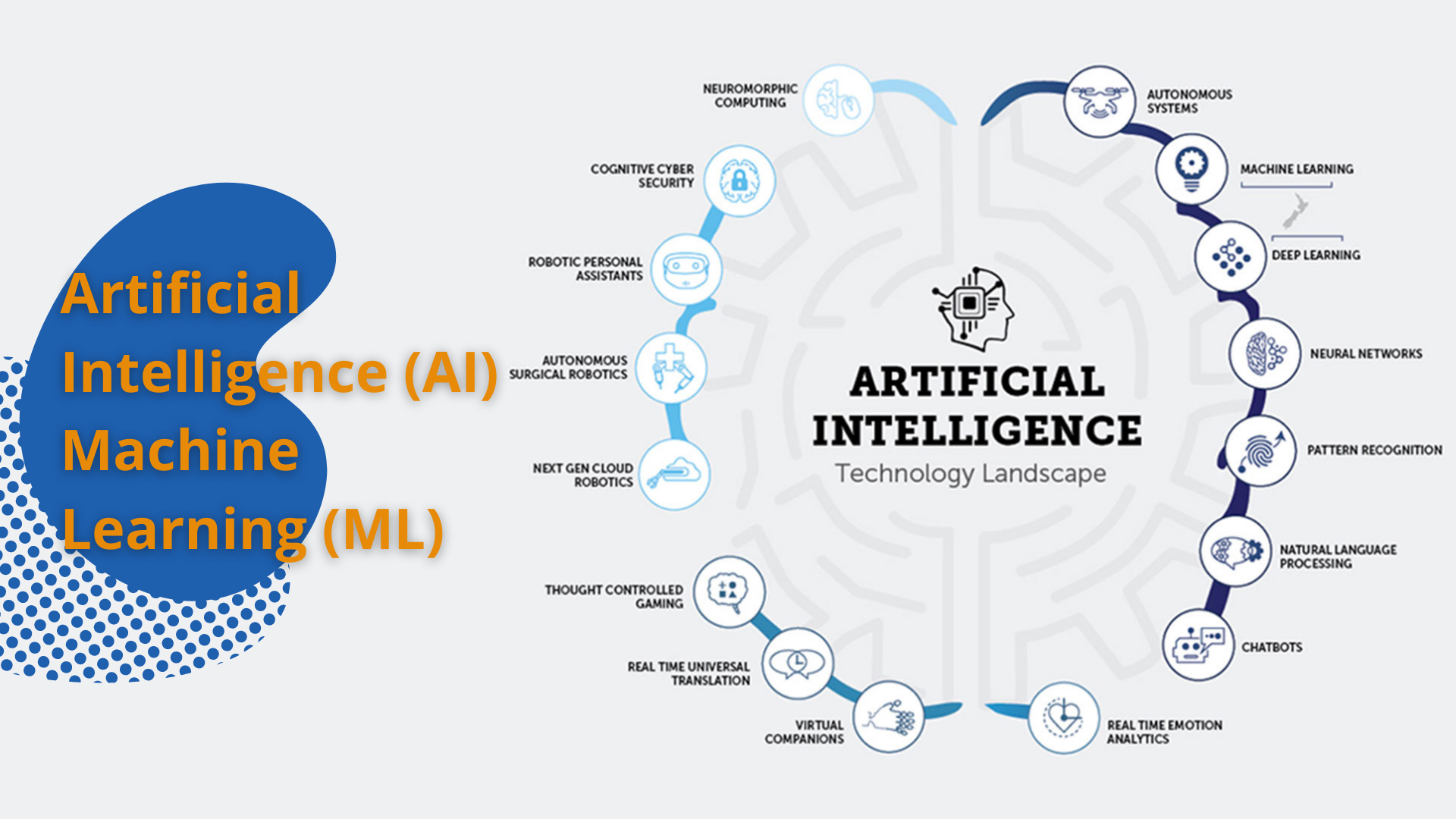
RVGS’s first approach was to understand the difference between artificial intelligence and machine learning. In our opinion the two terms are often used interchangeably, but they have subtly different applications.
Only once we understand this difference can we know which technology to use
Artificial Intelligence (AI): AI referred to the ability of programmed machines (computers or robots) to “think” like people and imitate human behavior. It was often used to describe systems endowed with intellectual processes, such as self-studying and problem-solving. Systems based on AI could assimilate, analyze, and use actual facts as well as knowledge to obtain further information. For instance, speech, voice, and image recognition all use artificial intelligence.
Machine Learning (ML): ML is a field of AI that was built on the idea that systems could learn from data, then make decisions in the absence of human participation.

Where is AI ineffective?
While AI had many strengths, it did fall short in certain circumstances. Our team found an approach to avoid any misplaced investments, hence it was necessary to understand what AI, cannot and should not do:
- Code software: Coding software involved understanding the ‘fundamental complexities of the real world’. AI couldn’t do that because AI couldnot understand our reality
- Generate creative content: Our team agrees that AI could create content using data. However, it couldn’t be creative (by which we mean write imaginative prose without guidelines)
- Make ethical decisions: Machines don’t have feelings. They lack a conscience. So, we couldn’t let them make moral judgments for people.
- Come to a final decision independently: While AI could help us, it cannot replace human resources . We cannot dotingly trust AI to make decisions on our behalf. We appreciated the fact that AI is still prone to making mistakes.
- Innovate and invent: AI could learn from data, but it had a limited ability to draw conclusions based on a given action. And it cannot be creative, nor come up with new solutions or ideas.
Step 2: Defined our needs:
Now that we understood the difference between Artificial Intelligence and Machine Learning, our team had to consider what we’re looking to achieve, alongside how these two technologies could help us with that.
First of all, we defined the problems we wanted AI to solve, to do this, our team tried to answer these five questions:
- What outcome(s) did we want to see?
- What are the main obstacles to achieving these outcomes?
- How can AI help us move towards success?
- How will we measure success?
- What data did we have, and what additional data did we need?
The answers to these questions helped us define our needs, then step towards the best solution for our company.
Step 3: Prioritized the main driver(s) of value
Once we’ve defined our needs, our team identified the potential business and financial benefits of our AI project. We considered all the possible AI implementations and tried to connect each initiative with concrete returns. We achieved this by focusing on near-term goals and illustrated either the financial or business value as best we could.
As we explored our objectives, team RVGS didn’t lose sight of value drivers as well as considered if machines in place of people could better handle specific time-consuming tasks.
We considered if we could effectively integrate a solution into our daily workflow, analyze how it fits into our processes, and explore whether adding an AI-based solution to our existing products or services would boost our operation over the long-term.
Step 4: Evaluated our internal capabilities
After prioritizing our objectives, we decided what approach works best for us such as:
- Building a new solution from scratch using internal resources
- Buying a ready-made product off the shelf
- Collaborating with a partner to develop your AI project
- Outsourcing the entire AI development process
Whichever approach seemed best, it was always worth researching existing solutions before taking the plunge with development. If we found a product that serves our needs, then the most cost-effective approach was likely a direct integration.
Step 5: Considered consulting a domain specialist
We already had a highly skilled developer team that could build our AI project off their own back. Regardless, it helped to consult with domain specialists before we started.
Developing AI was not the same as building typical software. AI was a hyper-specific specialism that was difficult to learn. It required lots of experience and a particular combination of skills to create algorithms that could teach machines to think, to improve, and to optimize our business workflows.
In case we had any doubts, we considered simply choosing to outsource our AI development to an agency specialized in big data, AI, and machine learning. AI agencies not only have the knowledge and experience to maximize our chance for success, but they also have a process that could help avoid any mistakes, both in planning and production.
Step 6: Prepared our data
AI was powerful however, AI algorithms only worked when we had a firm idea of what we were trying to achieve and if we had good examples for the algorithm to learn from. Therefore, before we started we made sure we had high-quality data that’s also clean.
We considered data to be clean if it met the following criteria:
- Free from incoherent information
- As accurate as possible
- With all the necessary attributes required for an algorithm to perform its task
Our team believes that even the most advanced algorithms in the world cannot give the results wanted if not provided with high-quality data to work from: that’s why our team made it a priority to organize, update, as well as expand our dataset frequently.
AI-based solutions were not a one-time operation. They were a series of scalable solutions but, to become that, our team needed to build their foundations on high-quality data as we believe that having more data, the better AI works.
Once you had our data prepared, we kept it secure. Our team was aware that standard security measures such as encryption, anti-malware apps, or a VPN may not be enough, so we invested in robust security infrastructure.
Step 7: We were ready to start.
By this step, our team was ready to start. However, when we were just starting out, we stayed selective in how we use AI: that meant not throwing all the data we had.
Instead we started with a small sample dataset and used artificial intelligence to prove the value that lies within. Then rolled out the solution strategically and with full stakeholder support.
Some of the challenges of Machine Learning implementations that were kept in mind while designing the solution by team RVGS:
- Selection of right algorithm: Though algorithms work in any generic conditions, there are specific guidelines available about which algorithm would work best under which circumstances. Improper selection of algorithms could produce garbage output after months of effort leading to massive loss of the entire effort and pushing the target timelines further.
- Selection of the right set of data: As they say,garbage in will produce garbage out, which is very well suited for the range of datasets for machine learning. The quality, amount, preparation, and selection of data were critical to the success of a machine learning solution. Data selection may be impacted by Bias. It was important to avoid selection bias and select the data which was entirely representative of the cases.
- Data Preprocessing: historical data was very messy and often consisted of missing values, valueless values, outliers and so on. Parsing, cleaning and preprocessing of such data can be a tedious job. Feature properties and value ranges were studied and techniques such as feature scaling was applied to prevent certain features from dominating the entire model.
- Data Labelling: Easy and more appropriate models were the ones used in Supervised ML algorithms. Unsupervised ML algorithm selection and implementation was a very tedious and lengthy process sometimes requiring several unsuccessful iterations. Supervised ML algorithms required data labeling. Data labeling was a manually intensive task but at the same time can’t be outsourced just like that.