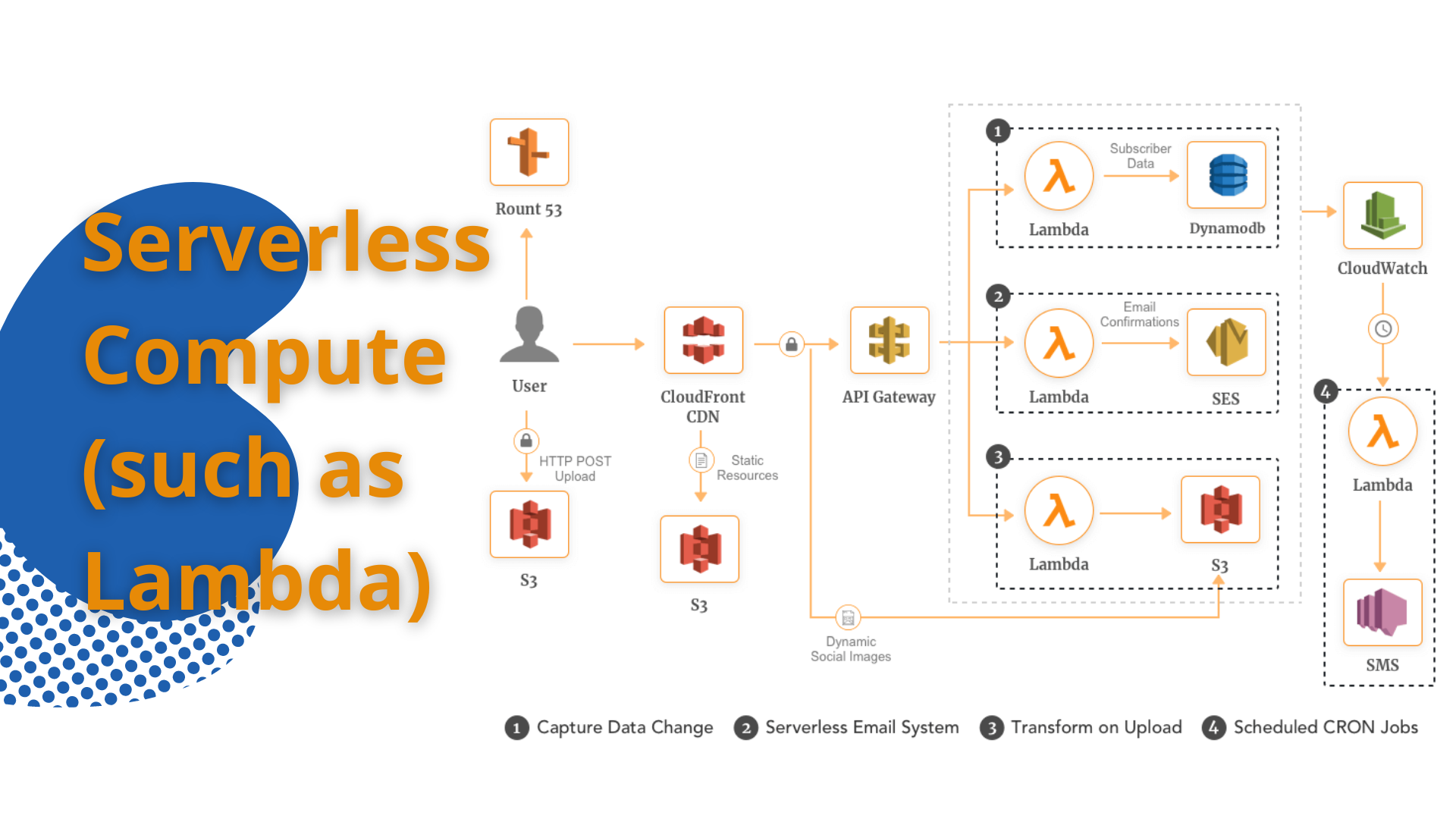
What is serverless?
Serverless is an approach implemented by team RVGS that aimed to address infrastructure and software architecture issues by:
- Using a managed compute service such as AWS Lambda, Azure Functions, Google Cloud Functions, IBM OpenWhisk, or Auth0 WebTask to execute code
- Leveraging third-party services and APIs in a more thoughtful way
- Applying serverless architectures and patterns.
Serverless to our team was about streamlining the complexity of traditional systems by abolishing the need to run servers and manage infrastructure as well as about helping our team focus on the core problem by reducing the amount of code we needed to write. By taking a serverless compute service and making use of various powerful single-purpose APIs and web services, our team built a loosely coupled, scalable, and efficient architecture quickly. In this way, we could move away from servers and infrastructure concerns, and focus primarily on code, which we believe is the ultimate goal behind serverless.
A serverless compute service, such as AWS Lambda, allowed us to execute code in response to events in a massively parallel way. Our team could respond to HTTP requests (using the AWS API Gateway), events raised by other AWS services, or invoked directly using an API. As with S3, there was no need to provision capacity for Lambda. There were no servers to monitor or scale, there was no risk to cost by over-provisioning, and there was no risk to performance by under-provisioning (PDF document).
The unit of scale in serverless was an ephemeral function that ran only when needed. This led our team to an interesting and noticeable outcome: the performance of code visibly and measurably affected its cost. The quicker the function stopped executing, the cheaper it was to run. This in turn, influenced the design of functions, approach to caching, and how many and which dependencies the function relies on to run much more than in traditional server-based systems.
Serverless compute functions were typically considered to be stateless. Team RVGS did not assume that local resources and processes remained each time a function ran.
We here at RVGS believe that statelessness is powerful because it allowed the platform to quickly scale to handle an ever-changing number of incoming events or requests. Having said that, the Lambda runtime did reuse its lightweight Linux containers, which ran functions under the hood. Our team when copied files over to the container’s filesystem (/tmp directory) or ran processes, found them again on subsequent instantiations.
Vendors, such as Amazon, Google, or Microsoft are in charge of the machines and the servers running in the background . Vendors are responsible for providing a highly-available compute infrastructure,including capacity provisioning and automated scaling.
In our experience serverless functions, or FaaS, are not just a platform as a service (PaaS) technology in disguise. The unit of scale between common PaaS systems and serverless functions is different. Traditional PaaS systems aren’t as granular, our team still had to work out the number of dynos or VMs to provision as well as took a lot longer to provision and deprovision as compared to serverless systems.
When a new serverless function needed to be created, it happened on the order of a few seconds for a cold function, and on the order of milliseconds for a warm function. The actual time it took to spin up a cold function depended on several factors, such as the language runtime (Lambda supports JavaScript, Python and Java) and the number of dependencies we needed to load.
Serverless cloud technologies such as Lambda were built on containers, but the advantage for our team was that we need not manage them. We could spend most of our time thinking about code and software architecture instead. It’s the vendor who puts in the most efficient way to allocate resources and computing capacity.
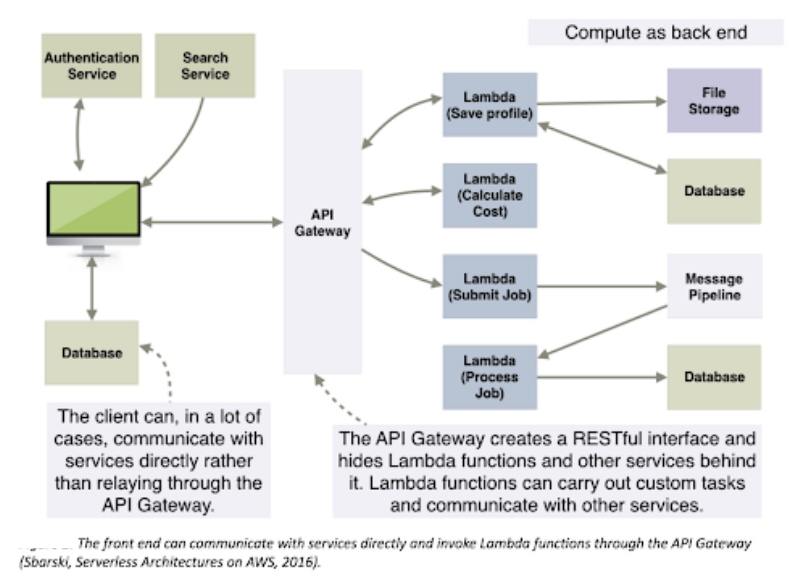
The 5 principles of serverless design implemented by team RV Global solutions:
Our team applied these principles to create an entire system (back end and front end) using a serverless approach.
1. Used a compute service to execute code on demand
A serverless compute service such as Lambda, Azure Functions, Auth0 WebTask, or Google Cloud Functions was used to execute code. Our team made sure not to run or manage any servers, VMs, or containers of our own. Our custom code entirely ran out of FaaS to gain the most benefit.
2. Wrote single-purpose, stateless functions
Our team followed the single responsibility principle (SRP) and only wrote functions that had a single responsibility. Such functions were easier to think about, test, and debug. We built a microservice around each function, but the appropriate level of granularity was decided based on requirements and context. Granular services, focused on a specific action, were our good bet.
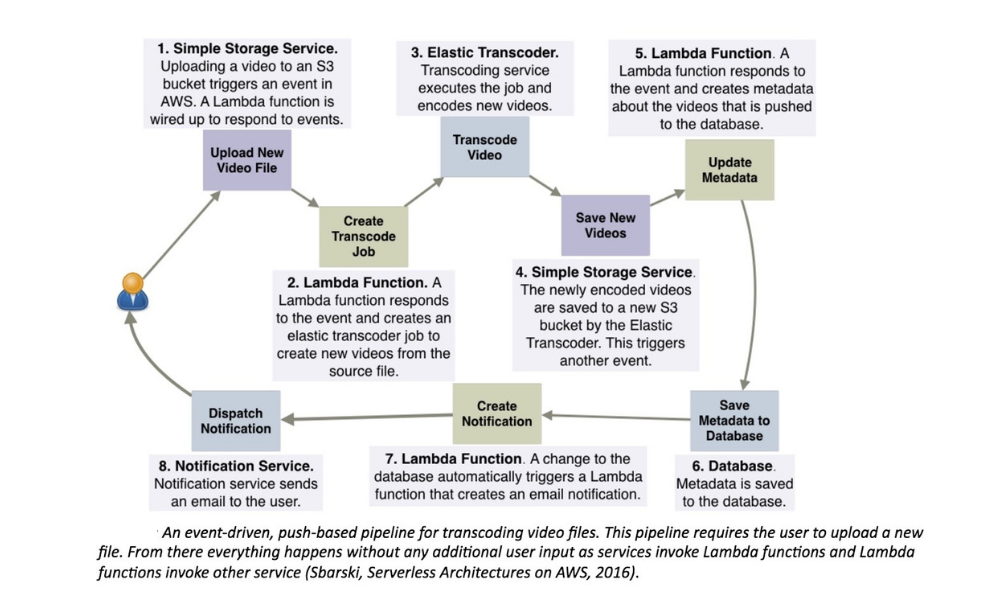
3. Designed push-based, event-driven pipelines
Created push-based, event-driven pipelines to carry out complex computations and tasks. Used a serverless compute service to orchestrate actions between different services, and tried to build in a way that creates event-driven pipelines. Our team avoided polling or manual intervention where possible
4. Created thicker, more powerful front ends
Moved as much logic as possible to the front end and made it smarter. Our front end was able to interact with services directly in order to limit the number of serverless functions.
5. Embraced third-party services
Our team tried to reduce the amount of custom code used, and instead leveraged services built by others, with one caveat: always made an assessment and thought about risks.By applying this principle we traded control for speed.